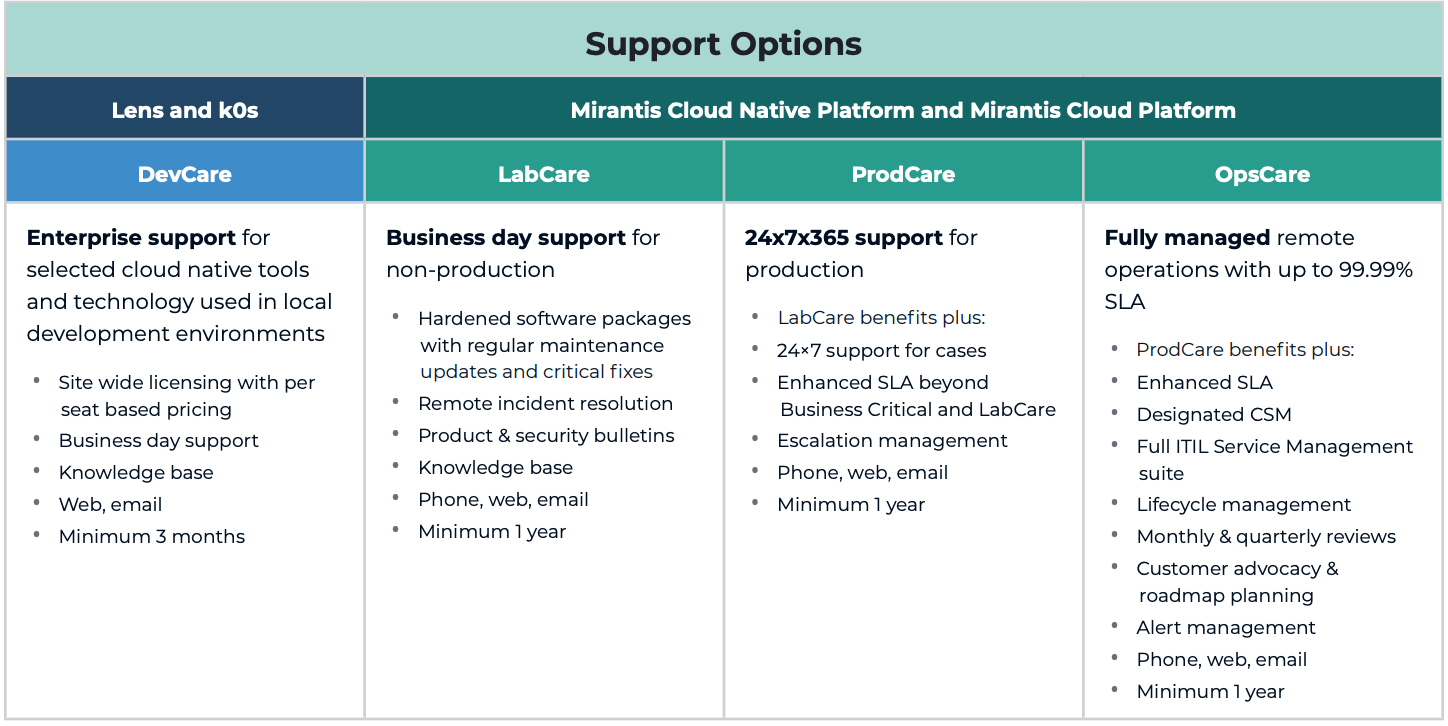
Enterprise Kubernetes delivers what upstream
Kubernetes lacks, providing a complete solution for secure enterprise
container and cloud computing at scale

Enterprise Kubernetes is open-source, “upstream”
Kubernetes, hardened and secured in various ways, and integrated with
other software and systems to provide a complete solution that fulfills
enterprise requirements for developing and hosting containerized
applications securely, at scale.
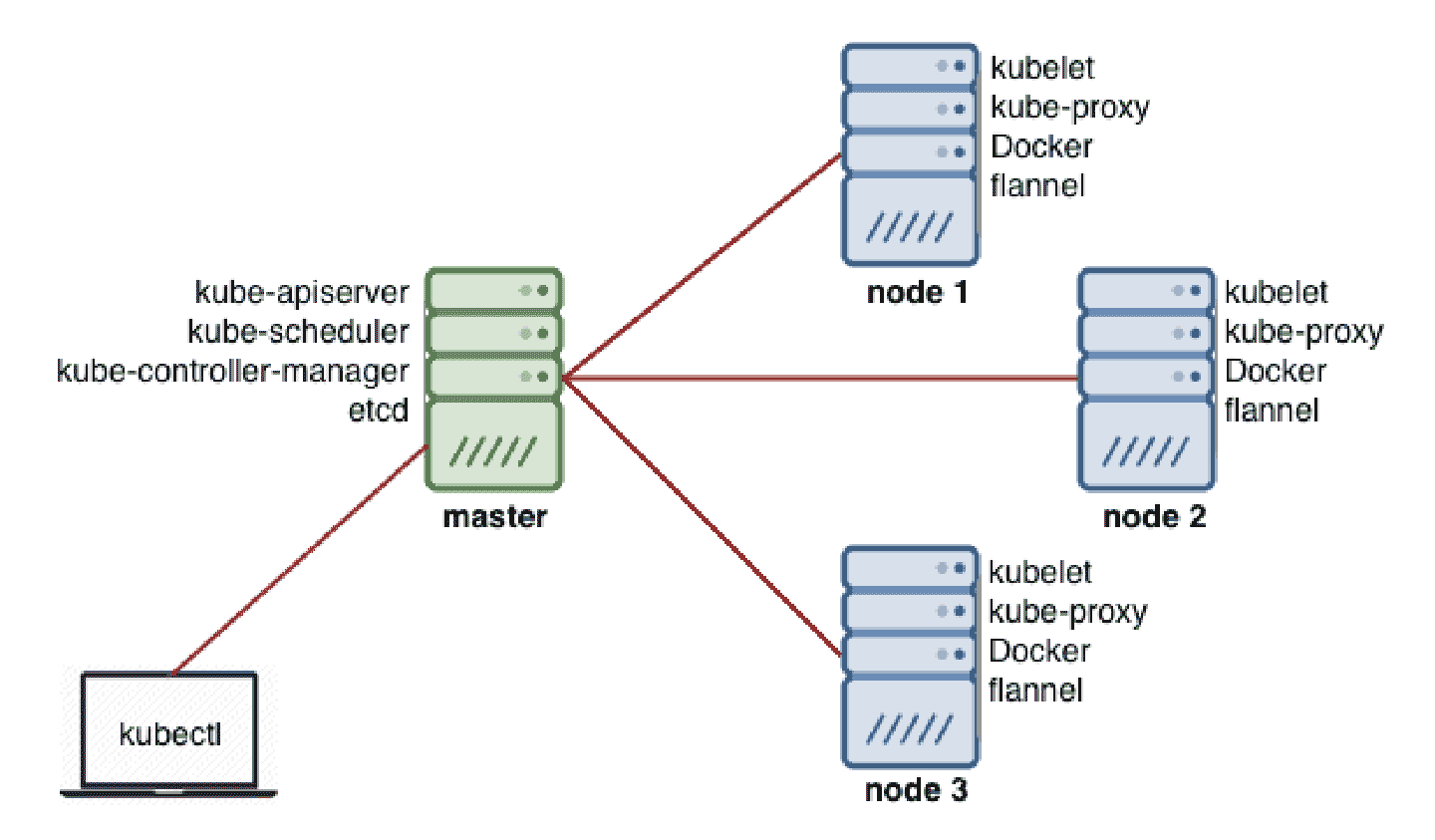
Kubernetes is incomplete by design
Kubernetes, by itself, provides a host of features for orchestrating
and managing container workloads, and for making them scalable and
resilient. But Kubernetes is incomplete by design.
Kubernetes is engineered in a modular way, with standard interfaces
for integrating fundamental components like container runtime,
networking, storage, and other subsystems and functionality.
Kubernetes promotes choice
This reflects the fact that Kubernetes evolved after, and partly in
response to the popularity of foundational technologies like Docker, and
was engineered to make those technologies work together seamlessly to
support large-scale, complex software projects and answer large
organizations’ requirements for resiliency and application lifecycle
automation.
You can think of Kubernetes as a “productization” of Google’s
original, internal-facing Borg project, realized against an emerging
landscape of container-related solutions. Today, Kubernetes lives at the
center of a vast Cloud Native Computing Foundation ecosystem of open
source and proprietary solutions that provide foundational capabilities,
extend Kubernetes functionality for practical use-cases, accelerate
software development, and deal with challenges of delivering and
operating Kubernetes at large scales, in forms that enterprises find
consumable.
Choice entails risk
Because Kubernetes is designed for flexibility, you can’t build a
working Kubernetes cluster without making choices. The Kubernetes
project has established some baselines and defaults that are widely
popular, like use of the open-source containerd runtime which shares DNA
with Docker Engine under a Kubernetes-standard Container Runtime
Interface (CRI). But they’re not compulsory, and for use-cases beyond “I
want to try out Kubernetes,” they may not be completely optimal.
Enterprises often don’t have the in-house technical expertise to feel
secure making such choices, and building (and then maintaining) their
own, customized enterprise Kubernetes platforms. While many have
succeeded in architecting working, small-scale solutions, they’re
(sensibly) leery of trying to use these in production.
Enterprise Kubernetes components
Here are some of the choices involved in assembling an enterprise Kubernetes platform:
Upstream hardening without lock-in
Open source software like Kubernetes goes through extensive, ongoing
testing by project contributors and maintainers. Each release is updated
frequently with bugfixes and limited backports. But the result isn’t
guaranteed perfect, and each successive Kubernetes release is deprecated
within a fairly short time. Because the ecosystem moves so quickly,
users can be challenged to stabilize and maintain reliable clusters over
time, free of known security vulnerabilities.
Producers of enterprise Kubernetes distributions can (or should)
take on responsibility for aggregating changes, hardening, and
supporting the versions of Kubernetes they provide to customers.
Important: Ideally, they should do this without adding substantial
proprietary code, constraining requirements (e.g., we’ll only support
this if you run it on our operating system) or elaborate “improvements”
that limit choice and put customers at a remove from upstream
innovation.
Container runtime – Docker-compatible, Linux or Windows, with built-in security
The container runtime is core software, running on each node, that
hosts individual containers. An enterprise Kubernetes needs a runtime
that’s entirely compatible with Docker-style container development
workflows and binaries, since that’s what enterprises are, with few
exceptions, using — plus flexibility to use other runtimes, if they
prefer. The default runtime should work comfortably on Linux and Windows
hosts to run Docker container binaries built for each platform. It
should support host hardware features like GPUs.
But that’s just the beginning. The runtime is the foundation of the
Kubernetes system, so an enterprise runtime is ideally situated to
provide many security and hardening features, like execution-policy
enforcement and content trust (i.e., the ability to prevent unsigned
container workloads from executing), FIPS 140-2 encryption (required by
regulated industries and government/military), and overall compliance
with established multi-criterion security benchmarks, like DISA STIG.
It can also be important that an enterprise runtime be able to
support modes of container orchestration besides Kubernetes — for
example, Swarm, which provides a simpler orchestration feature set,
already familiar to many Docker developers. This (plus support of
multiple orchestration types throughout the larger enterprise solution)
gives users more choice of how they want to onboard and support existing
workloads, and maximizes utility of existing and widespread skills.
Container network
An enterprise Kubernetes needs to provide a battle-tested container
networking solution — ideally, one that’s compatible with best-of-breed
ingress solutions, known to be able to scale to “carrier grade,” and
provides dataplanes for both Linux and Windows, enabling construction of
Kubernetes clusters with both worker node types. The ideal solution
needs to rigorously embrace Kubernetes-recommended, “principle of least
privilege” design, and support end-to-end communications authentication,
encryption, and policy management.
Ingress
Routing traffic from the outside world to Kubernetes workloads is the
job of Ingress: represented in Kubernetes as a standard resource type,
but implemented by one of a wide range of third party proxy solutions.
Enterprise-grade ingress controllers often extend the native
specification and add new features, such as the ability to manage
east/west traffic, more-flexible and conditional ways of specifying
routing, rewrite rules, TLS termination, ability to monitor traffic
streams, etc. To do this, they may implement sophisticated
architectures, with sidecar services on each node; and they may require
integration with monitoring solutions like Prometheus, tools like
Cert-manager, and other utilities to present complete solutions. An
enterprise Kubernetes needs to provide this kind of front-end routing
capability, both by implementing a best-of-breed ingress, and making it
manageable.
Enterprise Kubernetes and software development
Kubernetes vs. CaaS/PaaS
Full-on enterprise Kubernetes also needs to solve for the challenges
of container software development. Some distributions seem to approach
this with the attitude that Kubernetes development is inherently too
difficult for many developers, and hide Kubernetes beneath a so-called
CaaS (Containers as a Service) or PaaS (Platform as a Service)
framework. This is a generally quite prescriptive software layer that
provides templates for application design patterns, relevant component
abstractions, and connection rules (usually provided for a range of
programming languages and paradigms), plus software that operationalizes
these constructions on the underlying Kubernetes platform.
Such frameworks may help, initially, with legacy application
onboarding and certain kinds of early-stage greenfield application
development. But developers tend, over time, to find them restrictive:
good in some use-cases, but not in others. Using a PaaS extensively,
meanwhile, can mean locking applications, automation, and other large
investments of time, learning, and effort, into its limited — and
perhaps proprietary — framework, rather than Kubernetes’ standardized
and portability-minded native substrate. This, in turn, can lock
customers into a particular enterprise Kubernetes solution, perhaps with
a sub-optimal cost structure.
An important point to remember is that — if users want a CaaS or PaaS
(or a serverless computing framework or any other labor-saving
abstraction) — many mature open source solutions exist to provide these
capabilities on Kubernetes, while keeping investment proportionate to
benefit and avoiding lock-in. The best enterprise Kubernetes platforms
work hard to ensure compatibility with many solutions, giving their
users maximum freedom of choice.
Secure software supply chain
Teams developing applications to run on Kubernetes want and need to
work freely with workflow automation, CI/CD, test automation, and other
solutions, building pipelines that convey application components from
developer desktops, through automated testing, integration testing, QA,
staging, and delivery to production Kubernetes environments. Enterprise
Kubernetes solutions win with developers by providing maximum freedom of
choice, plus easy integration to Kubernetes and related subsystems that
work together to enforce policy and facilitate delivery of secure,
high-quality code.
Private container registry isn’t part of Kubernetes, per se, but can
be a foundational component of a secure software supply chain. An
enterprise-grade private registry offers practical features that
accelerate development while helping organizations maintain reasonable
control. For example, a registry may make it possible to
cryptographically sign curated images and layers, permitting only
correctly-signed assets to be deployed to (for example) staging or
production clusters — a feature called ‘content trust.’ It may be
configurable to automatically acquire validated images of popular open
source application components, scan these for vulnerabilities, and make
them available for use by developers only if no CVEs are found.
Coordinating functionality of this kind requires co-development of
registry and other components of the Kubernetes system, notably the
container runtime.
Visualization and workflow acceleration
Enterprise Kubernetes also needs to solve for developer and operator
experience. “Developer quality of life” features can range widely: from
APIs designed to simplify creation of self-service or operational
automation, to built-in metrics, to compatibility with popular heads-up
Kubernetes dashboards and other tools for speeding interactions with
Kubernetes clusters.
Enterprise Kubernetes at scale
Perhaps the most important feature of a complete enterprise
Kubernetes solution is that it solves problems of Kubernetes delivery,
administration, observability, and lifecycle management at enterprise
scales. That means anywhere from “a few small clusters” to hundreds or
thousands of clusters, perhaps distributed across a range of host
infrastructures, e.g., on-premises “private clouds” like VMware or
OpenStack, public clouds like AWS, bare-metal clouds, edge server racks,
etc.
What most enterprises seem to want is a seamless, fundamentally
simple “cloud” experience for Kubernetes delivery, everywhere: configure
a cluster with a few dialog boxes, provision users through integrations
with corporate directory, click “deploy,” quickly obtain credentials,
and get to work. Monitor and update the cluster non-disruptively through
the same interface. Keep the Kubernetes stack secure and fresh with
continuous updates.
Being able to do this consistently, across multiple infrastructures,
pays off hugely. Developers don’t need to worry about underlying
infrastructure mechanics: if they need to scale a cluster or tear it
down, the enterprise Kubernetes solution has API features for that.
Consistent Kubernetes clusters everywhere mean that applications and
their automation can be easily ported and reused. Consistency also
minimizes unknown and unmapped attack surfaces, improving security and
simplifying policy management and compliance.
What, then, is enterprise Kubernetes?
Expanding on our original definition, enterprise Kubernetes is real
Kubernetes, in a flexible, best-of-breed configuration, made “batteries
included” with careful choice of default components, and delivered ready
for production work, by systems designed to minimize the skill, time,
and overhead associated with managing this complex, but valuable group
of technologies.