How to deploy Kubernetes using Kubespray
Kubernetes is an open-source orchestration system that automates the process of deploying and maintaining containerized applications. It gives you the mechanism to schedule and run containers on clusters of several physical and/or virtual machines. For more information please read the official Kubernetes documentation.
Kubespray is a composition of Ansible playbooks, inventory, provisioning tools, and domain knowledge for generic OS/Kubernetes clusters configuration management tasks. It provides a highly available cluster, composable attributes and support for the most popular Linux distributions. It has become the de-facto production-ready Kubernetes installer that is trusted throughout the cloud-native community (10k stars on GitHub).
In this tutorial, we’ll show the steps required to deploy a Kubernetes cluster on UpCloud using Kubespray. The tutorial assumes that you have basic knowledge about Kubernetes and the different terminologies that comes with it but the steps are easy enough for beginners to follow along as well.
Setting up prerequisites
In principle, the steps in this guide can be divided into the following two main procedures which are required in order to set up a new Kubernetes cluster.
- Create the infrastructure
- Deploy Kubernetes
Before delving into the actual steps, clone Kubespray onto your own computer, for example by using the git command-line tool. If you do not already have git installed, you can use the command below to install git on Ubuntu or other Debian-based operating systems or check the git install guide for other OS options.
sudo apt install git-all
Then download the Kubespray package and change to the new directory.
git clone https://github.com/kubernetes-sigs/kubespray.git cd kubespray
You’ll also need to install Ansible and other dependencies. Luckily, Kubespray provides a handy list of the requirements which can be used to install all prerequisites with a single command. However, for this to work, you’ll first need to have Python’s package installer, pip, available.
sudo apt install python3-pip sudo pip3 install -r requirements.txt
If you face any issue while installing the prerequisites, please check the official Kubespray repository for troubleshooting steps.
Installing Terraform
Terraform is an infrastructure provisioning tool. It is used for building, changing, and versioning infrastructure safely and efficiently. Installing Terraform CLI on your computer provides you with all the tools you need to manage your infrastructure in the cloud.
To install Terraform, find the appropriate package for your system, download and install it.
For example, to install Terraform on most Linux systems, first, download the latest version.
wget https://releases.hashicorp.com/terraform/0.14.7/terraform_0.14.7_linux_amd64.zip
Then extract the binaries to a suitable location, such as /usr/local/bin and make sure it is included in your PATH environment variable. For example with the command below.
sudo unzip terraform_0.14.7_linux_amd64.zip -d /usr/local/bin
You can verify that the installation worked by listing Terraform’s available subcommands in a terminal.
terraform -help
Usage: terraform [-version] [-help][args] The available commands for execution are listed below. The primary workflow commands are given first, followed by less common or more advanced commands. ...
Setting up API access
For Terraform to be able to deploy cloud resources on your UpCloud account, you first need to grant it access. To do so, follow the steps below.
Create a separate API account in your UpCloud Control Panel
It is recommended to create a separate API user for Terraform to interact with UpCloud API during infrastructure deployment instead of using your main account. You can do this at the UpCloud Control Panel using the workspace member accounts. Your API account name and password are very much comparable to a traditional API ID and key pair with the added benefit of being able to set them freely yourself.
To create a new account, select People on the left side of the UpCloud Control Panel and follow the instructions. For more information, see this tutorial on how to get started with the UpCloud API.
Allow API Access to your UpCloud Account
Once you’ve created your API account, you will need to allow it to access the UpCloud API so that Terraform can create your infrastructure on UpCloud. For this purpose, make sure you select the Allow API connections on the new account and set it to All addresses to easily ensure later steps in this guide will work.

You can and for security reasons perhaps should restrict this later to your own IP.
Set up UpCloud user credentials
Lastly, you’ll need to pass the new API account credentials to Terraform. Use the commands below to export your new API username and password as environment variables in your current shell session. The username and password will then be accessible to Terraform CLI when creating your cluster.
export TF_VAR_UPCLOUD_USERNAME=export TF_VAR_UPCLOUD_PASSWORD=
Note: The credentials above are in plaintext. It is advisable to store the username and password Base64 encoded for more permanent use.
Overview of the infrastructure
A cluster in Kubernetes is composed of multiple control plane and worker nodes. Control plane nodes are nodes that control and manage a set of worker nodes (workloads runtime) and worker nodes are nodes that run containerized applications.
An example of a Kubernetes cluster setup could look like the following.
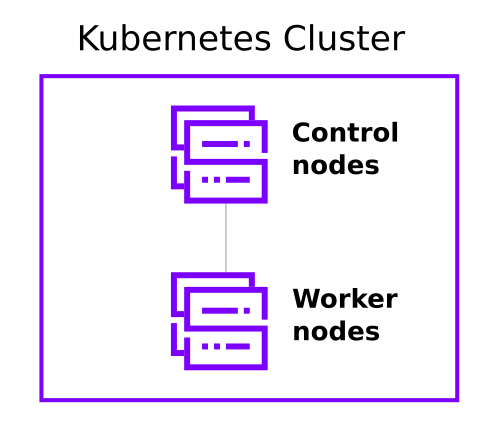
You need to decide the number of both control plane and worker nodes for your cluster. In this post, we will use one control plane node and three worker nodes.
To create the Kubernetes cluster, you need to make sure you have Terraform CLI installed on your system as well as the proper configuration for your cluster. Terraform helps us to define infrastructure as a code. Defining infrastructure as code brings many advantages such as simple editing, reviewing, and versioning, as well as easy sharing amongst team members.
Configuring the cluster
Next, we’ll set up the configuration for our cluster. To avoid modifying the template files, let us copy the required files into a new directory and do the changes there.
Create a directory called my-upcloud-cluster as follows. The CLUSTER variable here is a shorthand for our directory name. If you want to name your directory differently, just change the next line and the rest of the configuration works the same.
CLUSTER=my-upcloud-cluster
mkdir inventory/$CLUSTER
Copy the sample inventory and the default cluster configuration to the new directory.
cp -r inventory/sample inventory/$CLUSTER cp -r contrib/terraform/upcloud/* inventory/$CLUSTER/
Change your working directory to the new configuration directory and edit the cluster-settings.tfvars file to match your requirements.
cd inventory/$CLUSTER
vim cluster-settings.tfvars
The following are the main Terraform variables that you can change in cluster-settings.tfvars file.
- hostname: A valid domain name, e.g. example.com. The maximum length is 128 characters.
- template_name: The name or UUID of a base image.
- username: A user to access the nodes e.g., via SSH. Note that the username kube is reserved by kubernetes.
- ssh_public_keys: One or more public SSH keys is required to be able to access and provision the machines after deployment.
- zone: The zone where the cluster will be created. Check the available zones for reference.
- machines: The Cloud Servers that will be provisioned. Contain the list of machines composing the cluster. The key of this object will be used as the name of the machine.
- node_type: The role of this node (master|worker, in Kubespray and hence in this guide called “master” due to legacy naming of the control plane — is likely to change in the future).
- cpu: Number of CPU cores.
- mem: Memory size in MB.
- disk_size: The size of the storage in GB.
For example, to create a cluster with two control plane nodes, three worker nodes, and each node with 2 cores, 4GB memory, and 250GB disk size, replace the machines section in the variables with the following code snippet.
machines = {
"master-0" : {
"node_type" : "master",
#number of cpu cores
"cpu" : "2",
#memory size in MB
"mem" : "4096"
# The size of the storage in GB
"disk_size" : 250
},
"worker-0" : {
"node_type" : "worker",
#number of cpu cores
"cpu" : "2",
#memory size in MB
"mem" : "4096"
# The size of the storage in GB
"disk_size" : 250
},
"worker-1" : {
"node_type" : "worker",
#number of cpu cores
"cpu" : "2",
#memory size in MB
"mem" : "4096"
# The size of the storage in GB
"disk_size" : 250
},
"worker-2" : {
"node_type" : "worker",
#number of cpu cores
"cpu" : "2",
#memory size in MB
"mem" : "4096"
# The size of the storage in GB
"disk_size" : 250
}
}Don’t forget to replace the value of the ssh_public_keys variable with your public SSH key as it will be used to ssh to each machine when installing Kubernetes using Kubespray.
Deploying the cluster
Now that the configurations are done, you can start deploying your cluster.
Initialise your configuration directory
The terraform init command is used to initialize a working directory containing Terraform configuration files. It will download and install the UpCloud Terraform provider plugin.
Run the following command to initialize Terraform.
terraform init
Verify your infrastructure
The terraform plan command verifies your configuration is syntactically correct and creates an execution plan. Terraform performs a refresh, unless explicitly disabled, and then determines what actions are necessary to achieve the desired state specified in the configuration files.
Run the following command to see your execution plan:
terraform plan --var-file cluster-settings.tfvars \ -state=tfstate-$CLUSTER.tfstate
Deploy the infrastructure
The terraform apply command is used to apply the changes required to reach the desired state of the configuration or the predetermined set of actions generated by a Terraform execution plan. It creates new or makes changes to the existing infrastructure as defined in your configuration.
Run the following command to create your cluster and answer yes when asked to confirm:
terraform apply --var-file cluster-settings.tfvars \ -state=tfstate-$CLUSTER.tfstate
Once Terraform has finished deploying, you can go and check your cluster resources at your UpCloud Control Panel. The following figure shows the four servers (one control plane and three worker nodes) created by Terraform.

You should also get an inventory file named inventory.ini that you can use with Kubespray. We will use the inventory file to set up the Kubernetes cluster later.
ls
cluster-settings.tfvars inventory.ini sample
terraform.tfstate tfstate-my-upcloud-cluster.tfstateSetting up Kubernetes with Kubespray
Ansible is an open-source software provisioning, configuration management, and application-deployment tool enabling infrastructure as code.
Configure Ansible
Set ANSIBLE_CONFIG environment variables to Kubespray’s ansible configuration file as follows:
export ANSIBLE_CONFIG=../../ansible.cfg
Check that you have basic SSH connectivity to the nodes. You can do this by running the following ansible command.
ansible -i inventory.ini -m ping all
You should see similar to the following figure if all nodes are reachable.
master-0.example.com | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": false,
"ping": "pong"
}
worker-0.example.com | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": false,
"ping": "pong"
}
worker-1.example.com | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": false,
"ping": "pong"
}
worker-2.example.com | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/bin/python3"
},
"changed": false,
"ping": "pong"
}
Deploy Kubernetes
You can now deploy Kubernetes with Kubespray using the inventory file generated during the Terraform apply step as follows.
Note: if you use a different user to access the nodes other than the default ubuntu, please replace ubuntu with the new user in the inventory.ini file.
ansible-playbook -i inventory.ini ../../cluster.yml -b -v
Then sit back and relax while Ansible and Kubespray do all the heavy lifting!
Once done, you will see a play recap of the deployment like in the screenshot below.
Accessing your new Kubernetes cluster
By default, Kubespray configures kube-master hosts with access to kube-apiserver via port 6443 as http://127.0.0.1:6443. You can connect to this from one of the master nodes.
Get the IP address of one of the master nodes and SSH to it.
For example, the following script retrieves the IP of master-0 node from the inventory file and opens an SSH connection to it using the default username.
# get the IP address of master-0
ip=$(grep -m 1 "master-0" inventory.ini | grep -o '[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}' | head -n 1)
# ssh to master-0 node
ssh ubuntu@$ipOnce you are logged into one of the master nodes, you can run any of the kubectl commands. For example, use the command below shows the list of nodes in the cluster.
sudo kubectl get nodes
NAME STATUS ROLES AGE VERSION master-0.example.com Ready control-plane,master 10m v1.20.5 worker-0.example.com Ready 10m v1.20.5 worker-1.example.com Ready 10m v1.20.5 worker-2.example.com Ready 10m v1.20.5
Accessing Kubernetes Cluster from a workstation
While in the example above, we logged into one of the nodes in the cluster, it’s also possible to command Kubernetes right from your own workstation. To make this work, simply copy the /etc/kubernetes/admin.conf from a master node to your workstation and use it with kubectl.
The following script does the trick.
# get the IP address of master-0
ip=$(grep -m 1 "master-0" inventory.ini | grep -o '[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}' | head -n 1)
# copy /etc/kubernetes/admin.conf file on the local system
ssh ubuntu@$ip 'sudo cat /etc/kubernetes/admin.conf' > admin.confMake sure you have installed the kubectl tool on your local machine.
If you haven’t done so already please follow the instructions here. Once you have installed the tool you can interact with your cluster.
To access your Kubernetes cluster remotely, you need to tell kubectl where your configuration file is. One way to do that is to point the KUBECONFIG environment variable to your cluster kubeconfig file as shown below:
export KUBECONFIG=admin.conf
One last thing you need to do before you run any of the kubectl commands is to replace the Kubernetes API IP address in the admin.conf with one of the control plane node IP addresses.
Open admin.conf file with your favourite text editor and replace 127.0.0.1 with the IP address you get from above.
vim admin.conf
Alternatively, if you already have the IP address of the first master node save in the $ip variable. You can swap the 127.0.0.1 IP with the IP saved in the variable using the following command.
sed -i "s/127.0.0.1/$ip/g" admin.conf
With the master node IP set in the admin file, you are ready to start playing with your cluster from your local machine!
For example, use the following command to show a list of namespaces in your cluster.
kubectl get namespace
NAME STATUS AGE default Active 12m kube-node-lease Active 12m kube-public Active 12m kube-system Active 12m
Congratulations, you now have a fully functional production-ready Kubernetes cluster up and running!
Teardown
Once you are done testing the cluster and no longer need it, you can use Terraform to tear down the deployed infrastructure.
The terraform destroy command is used to destroy the Terraform-managed infrastructure. It terminates resources defined in your Terraform configuration and performs the reverse of what the terraform apply does.
You can tear down your infrastructure using the following Terraform command:
terraform destroy --var-file cluster-settings.tfvars \ -state=tfstate-$CLUSTER.tfstate ../../contrib/terraform/upcloud/
After deletion, you can always use the same configuration files to teak and modify your cluster and deploy it again with a moments notice!